
In einer Rechnungsanwendung, die Rechnungen erstellt und Zahlungen verwaltet, sind Zuverlässigkeit, Konsistenz und Fehlertoleranz von größter Bedeutung. Das System muss sicherstellen, dass alle geschäftskritischen Aktionen – wie die Erstellung von Rechnungen, die Verarbeitung von Zahlungen und die Aktualisierung von Salden – zuverlässig ausgeführt und übermittelt werden, selbst bei Netzwerkausfällen, Systemabstürzen oder vorübergehenden Serviceunterbrechungen.
Wenn Nachrichten fehlschlagen, müssen sie erneut versucht werden, aber je nach Systemarchitektur kann dies ein manueller und fehleranfälliger Prozess sein. In vielen traditionellen Nachrichtensystemen liegt die Last des erneuten Versuchs oder der Behebung fehlgeschlagener Nachrichten bei den Entwicklern oder Systemadministratoren. Dieser Ansatz stellt zwar sicher, dass keine Nachrichten verloren gehen, erfordert aber eine aktive Verwaltung und Überwachung.
Um eine robuste Nachrichtenverarbeitung zu gewährleisten und den erwähnten manuellen Aufwand zu reduzieren, implementieren wir bei Nitrobox das Outbox-Muster an kritischen Punkten. Es trägt entscheidend dazu bei, dass Ereignisse sicher und konsistent an andere Microservices und externe Systeme wie Benachrichtigungsdienste, Zahlungsanbieter und Buchhaltungssysteme übermittelt werden, indem eine einzige Transaktion verwendet wird, bei der alle Aktionen gemeinsam oder gar nicht ausgeführt werden.
Inhaltsverzeichnis
Die Herausforderung von Nachrichtenfehlern in Verteilten Systemen
Häufige Ursachen von Nachrichtenfehlern in der Microservices-Kommunikation
In unserem nachrichtenbasierten System werden Nachrichten von einem Dienst zum anderen über einen Message Broker wie ActiveMQ oder Azure Service Bus gesendet. Manchmal schlagen diese Nachrichten aus verschiedenen Gründen fehl, wie zum Beispiel:
- Netzwerkprobleme: Temporäre Verbindungsprobleme zwischen den Diensten.
- Dienst nicht verfügbar: Der Zielservice könnte ausgefallen sein.
- Fehler in der Geschäftslogik: Der empfangende Dienst könnte die Nachricht aufgrund einer Validierungsfehlermeldung ablehnen.
- Systemüberlastung: Die Nachrichtenwarteschlange oder der Dienst ist möglicherweise überlastet und kann die Nachricht in diesem Moment nicht verarbeiten.
Dead Letter Queue (DLQ) – Warum sie nicht immer ausreicht
Wenn eine Nachricht fehlschlägt, wird sie in eine Dead Letter Queue (DLQ) weitergeleitet – eine spezielle Warteschlange, die als Zwischenspeicher für nicht verarbeitbare Nachrichten dient. Dies verhindert den Verlust von Nachrichten, führt jedoch zu einem potenziellen Problem: Manuelle Intervention ist erforderlich.
Sobald eine Nachricht in der DLQ landet, muss jemand:
- Die Nachricht untersuchen: Verstehen, warum sie fehlgeschlagen ist.
- Das Problem beheben: Dies kann die Behebung von Systemfehlern, die Wiederherstellung eines nicht verfügbaren Dienstes, die Korrektur der Nachricht selbst oder im schlimmsten Fall die Bereinigung von Inkonsistenzen umfassen.
- Die Nachricht erneut senden: Nach der Problemlösung muss die Nachricht manuell in die Hauptwarteschlange zurückgeführt oder erneut verarbeitet werden.
Dieser Prozess ist zeitaufwendig, fehleranfällig und kann zu Verzögerungen in der Gesamtleistung des Systems führen. Je nach Kritikalität der Nachricht können diese Verzögerungen erhebliche geschäftliche oder technische Probleme verursachen.
Ein noch schwerwiegenderes Problem tritt auf, wenn ein Event als Folge einer Statusänderung gesendet wird:
Das Event könnte vor der Persistierung der Statusänderung in der Datenbank gesendet werden – oder umgekehrt. Falls nach dem ersten, aber vor dem zweiten Schritt ein Fehler auftritt, entstehen zwei potenzielle Inkonsistenzen:
- Der Zustand wurde aktualisiert, aber kein Event wurde gesendet, sodass andere Systemkomponenten nicht benachrichtigt werden.
- Ein Event wurde gesendet, aber der Zustand nicht aktualisiert, was zu Inkonsistenzen führt, wenn andere Dienste oder Systeme den Zustand auslesen.
Diese Szenarien machen deutlich, dass eine Dead Letter Queue allein nicht ausreicht, um ein robustes und fehlertolerantes System zu gewährleisten.

Was ist das Outbox Pattern? Ein zentrales Muster für ereignisgesteuerte Architekturen
Das Outbox Pattern ist eine Technik, die eine zuverlässige Event-Zustellung zwischen Diensten sicherstellt, insbesondere in Systemen, in denen ein Service ein Event (z. B. „Rechnung erstellt“) veröffentlichen muss, nachdem eine lokale Transaktion (z. B. das Erstellen einer Rechnung im Abrechnungssystem) abgeschlossen wurde.
So funktioniert es:
1. Nachrichtenpersistenz mit der Outbox-Tabelle
- Anstatt Nachrichten direkt an den Message Broker zu senden, schreibt der Service die Nachricht in eine spezielle Outbox-Tabelle in seiner lokalen Datenbank. Dadurch wird sichergestellt, dass die Nachricht persistiert und nicht verloren geht, falls während der Übertragung ein Fehler auftritt. Die Outbox-Tabelle fungiert als Zwischenspeicher für zu sendende Nachrichten.
2. Sicherstellung der Transaktionsintegrität mit Atomaren Transaktionen
Um sicherzustellen, dass Nachrichten nur gesendet werden, wenn die Geschäftsoperation erfolgreich ist, wird das Schreiben der Nachricht in die Outbox-Tabelle als Teil derselben Transaktion wie die Geschäftsoperation durchgeführt.
Beispiel: Wenn ein Service eine Bestellung verarbeitet und eine Nachricht an einen anderen Service senden muss, wird die Bestellung in der Haupttabelle gespeichert, und die Nachricht wird gleichzeitig in die Outbox-Tabelle geschrieben – innerhalb derselben atomaren Transaktion.
3. Automatisierte Nachrichtenverarbeitung und Wiederholungen für höhere Zuverlässigkeit
- Ein Background-Worker (oder ein ähnlicher Mechanismus) scannt regelmäßig die Outbox-Tabelle nach nicht gesendeten Nachrichten. Sobald eine Nachricht erkannt wird, sendet der Worker sie an den Message Broker und markiert sie in der Outbox-Tabelle als erfolgreich gesendet.
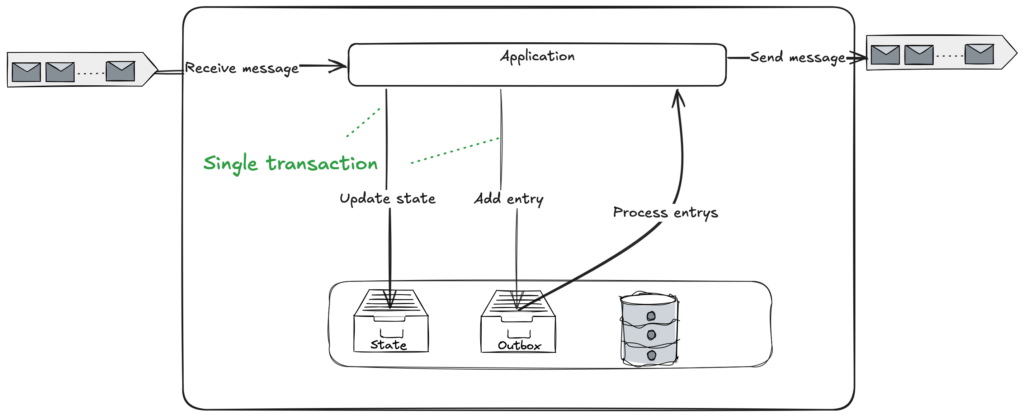
4. Automatische Wiederholungen bei Fehlern für höhere Zuverlässigkeit
Falls eine Nachricht nicht gesendet werden kann (z. B. aufgrund von Netzwerkproblemen oder Dienstausfällen), wiederholt der Worker den Sendeversuch. Dieser Retry-Mechanismus kann mit Exponential Backoff oder anderen Strategien konfiguriert werden, um eine Überlastung des Systems zu vermeiden. Da die Wiederholungen automatisch erfolgen, entfällt die Notwendigkeit einer manuellen Intervention.
5. Garantierte Zustellung
Da die Nachricht vor dem Sendeversuch in die Outbox-Tabelle geschrieben wird und Wiederholungen automatisiert erfolgen, gewährleistet das Outbox Pattern eine eventuelle Konsistenz, ohne dass eine Dead Letter Queue (DLQ) manuell verwaltet werden muss. Sobald das Problem (z. B. ein Dienst- oder Netzwerkfehler) behoben ist, wird die Nachricht ohne manuelles Eingreifen zuverlässig zugestellt.
Wann sollte das Outbox Pattern in der Microservices-Kommunikation verwendet werden?
Outbox Pattern vs. Event Sourcing – Welche Lösung ist die richtige?
Während das Outbox Pattern viele Vorteile bietet, ist es nicht immer die beste Wahl für jedes Szenario. Es ist besonders nützlich, wenn:
Atomare Operationen über Dienste hinweg erforderlich sind: Aktionen (wie das Senden einer Nachricht) sollen nur stattfinden, wenn die zugrunde liegende Geschäftstransaktion erfolgreich ist.
Automatische Wiederholungen erforderlich sind: Manuelle Eingriffe bei fehlgeschlagenen Nachrichten sollen vermieden werden, insbesondere in Systemen mit hohem Durchsatz.
Eventuelle Konsistenz akzeptabel ist: Es ist tolerierbar, dass Nachrichten verzögert verarbeitet werden, solange sie letztendlich zugestellt werden.
Andererseits, in Systemen mit extrem hohem Nachrichtenaufkommen oder wenn Nachrichten mit sofortiger und garantierter Zustellung verarbeitet werden müssen, kann Event Sourcing die geeignetere Wahl sein.
Implementierung des Outbox Patterns in Spring Boot
Wie Nitrobox das Outbox Pattern für zuverlässige Nachrichtenübermittlung nutzt
Bei Nitrobox haben wir Spring Boot Starter Libraries entwickelt, die die Outbox-Funktionalität für Services mit MySQL oder MongoDB bereitstellen. Der Starter unterstützt mehrere Outboxen und ist hochgradig konfigurierbar.
Zusätzlich gibt es eine Bibliothek, die API-Endpunkte zur Verwaltung von Outbox-Einträgen bereitstellt, sowie eine weitere Bibliothek, die speziell für das Senden von AMQP-Nachrichten entwickelt wurde.
In addition there is also a library that provides API endpoints to maintain outbox entries and a library intended to be used when sending AMQP messages.
Modul | Beschreibung |
|---|---|
core | Die Kernfunktionalität der Outbox |
mysql | MySQL-Implementierung |
mongodb | MongoDB-Implementierung |
mvc | Stellt einen Controller mit Endpunkten zur Verwaltung von Outbox-Einträgen bereit |
amqp | Stellt automatisch konfigurierte Spring Beans bereit, um die Nutzung des Outbox-Starters zu erleichtern beim Senden von AMQP-Nachrichten |
Statusmodell
Für die Outbox-Einträge verwenden wir das folgende Statusmodell:
ENQUEUED-Der Outbox-Eintrag wurde in der Outbox gespeichert und wird verarbeitet.PROCESSING– Der Outbox-Eintrag wird derzeit verarbeitet.PROCESSED-Der Outbox-Eintrag wurde erfolgreich verarbeitet.FAILED– Die Verarbeitung des Outbox-Eintrags ist fehlgeschlagen (z. B. aufgrund einer ausgelösten Ausnahme).
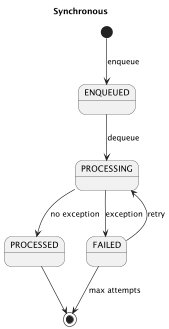
Das Statusmodell ist entscheidend für die korrekte Verarbeitung von Ereignissen. Durch die Integration dieses Modells kann jeder Eintrag in der Outbox während seines gesamten Lebenszyklus nachverfolgt werden, sodass Zeitstempel bei Statusänderungen präzise erfasst werden. Dies stellt nicht nur sicher, dass Ereignisse korrekt verarbeitet werden, sondern bietet auch eine Audit-Trail-Funktion, die für Fehlerbehebung und Überwachung nützlich ist. Durch die Nachverfolgung von Status und Zeitstempeln können Entwickler Fehlerquellen leichter identifizieren und die Kontrolle über den Ereignisfluss verbessern.
Unsere Konfiguration für die Outbox-Verarbeitung
Die Outbox muss die Flexibilität bieten, fehlgeschlagene Einträge erneut zu versuchen, eine Überlastung der empfangenden Systeme zu verhindern und die Möglichkeit zu bieten, erfolgreich verarbeitete Einträge nach einer bestimmten Zeit zu löschen.
Daher stehen die folgenden Konfigurationsparameter zur Verfügung:
| Eigenschaft | Beschreibung |
|---|---|
| expireAfter | Zeitspanne, nach der PROCESSED-Einträge gelöscht werden. |
| circuit-breaker | Optionale Circuit-Breaker-Konfiguration, die verwendet wird, wenn ENQUEUED-Einträge automatisch aus der Warteschlange entfernt oder FAILED-Einträge erneut versucht werden. Siehe CircuitBreaker. |
| ignoreExceptions | Liste der Ausnahme-Klassen, die ignoriert werden. Wird eine konfigurierte Ausnahme bei der Verarbeitung eines Eintrags ausgelöst, wird der Eintrag nicht erneut versucht und nach expireAfter gelöscht. Ignorierte Ausnahmen werden zudem nicht als Fehler im Circuit Breaker registriert. Hinweis: Der Eintrag wird dennoch als FAILED markiert. |
| retry.maxAttempts | Maximale Anzahl von Versuchen, einschließlich des ersten Aufrufs als erster Versuch. |
| retry.processingStaleAfter | Zeitspanne, nach der PROCESSING-Einträge erneut versucht werden. Dies setzt voraus, dass die Verarbeitung des Eintrags abgebrochen wurde (z. B. durch das Herunterfahren der Anwendung). Wenn auf 0 gesetzt, werden Einträge im Status PROCESSING nicht erneut versucht. |
| retry.backoff.initialInterval | Initiales Intervall der Retry-Backoff-Strategie. |
| retry.backoff.multiplier | Multiplikator der Retry-Backoff-Strategie. |
| retry.backoff.maxInterval | Maximales Intervall der Retry-Backoff-Strategie. |
| retry.schedule.trigger.interval | Periodisches Trigger-Intervall des Retry-Jobs. Das Intervall wird zwischen den tatsächlichen Abschlusszeiten gemessen (Fixed-Delay). |
| retry.schedule.trigger.initialDelay | Initiale Verzögerung nach dem Start der Anwendung für den Retry-Job. |
| retry.schedule.lock.atMostFor | Shedlock-Konfiguration des Retry-Jobs. Die Sperre bleibt bestehen, bis diese Dauer abläuft. Danach wird sie automatisch freigegeben (der Prozess, der sie hielt, ist höchstwahrscheinlich abgestürzt, ohne sie freizugeben). |
| retry.schedule.lock.atLeastFor | Shedlock-Konfiguration des Retry-Jobs. Die Sperre bleibt mindestens für diese Dauer bestehen, selbst wenn die Aufgabe, die die Sperre hält, früher abgeschlossen wird. |
Eine Beispielkonfiguration in der application.yaml könnte folgendermaßen aussehen:
outbox:
outboxes:
InboxDocumentProvisioned:
expireAfter: 30d
circuit-breaker:
slidingWindowSize: 100
minimumNumberOfCalls: 10
permittedNumberOfCallsInHalfOpenState: 3
slowCallDurationThreshold: PT15S
retry:
maxAttempts: 5
processingStaleAfter: 10m
backoff:
initialInterval: 1m
multiplier: 1.5
maxInterval: 5m
schedule:
trigger:
interval: 30s
initialDelay: 30s
lock:
atMostFor: 10m
atLeastFor: 10s
Um zu vermeiden, dass all diese Optionen jedes Mal manuell definiert werden müssen, stehen einige vordefinierte Templates zur Verfügung:
- default – Allgemeine, vielseitig einsetzbare Konfiguration
- web – Konfiguration für Outboxen, die HTTP-Anfragen senden
- amqp – Konfiguration für Outboxen, die AMQP-Nachrichten senden
Vordefinierte Eigenschaften können durch explizite Definition überschrieben werden.
outbox:
outboxes:
OutboxDefault:
type: default
expireAfter: P50D
Fazit
Nachdem wir nun erklärt haben, wie der Outbox Spring Boot Starter konfiguriert wird, solltest du ein gutes Verständnis dafür haben, was das Outbox Pattern leisten kann und wie es in eine ereignisgesteuerte Architektur integriert wird.
Im nächsten Blogpost werden wir uns mit der konkreten Implementierung des Outbox Starters befassen. Bleib dran, um zu sehen, wie alles in der Praxis umgesetzt wird!
